


Ing. Diógenes Álvarez Solórzano
Profesor del Instituto Tecnológico de Costa Rica (TEC)
Resumen
Este documento presenta el diseño e implementación del modelo de redes neuronales Alfa-Pi-Mi, para personalizar y optimizar el aprendizaje de estudiantes de ingeniería industrial, aplicando inteligencia artificial. Utilizando redes neuronales, el modelo identifica patrones de aprendizaje y propone estrategias personalizadas. Este trabajo detalla la arquitectura del modelo, incluyendo el impacto de las variables de entrada, las funciones de activación y los métodos de optimización utilizados. Una prueba piloto evidenció mejoras significativas en áreas clave como optimización y estadística. Además, se analizan las limitaciones técnicas, éticas y su alineación con los principios de la Industria 5.0.
Palabras clave: redes neuronales, aprendizaje personalizado, inteligencia artificial en educación, Alfa-Pi-Mi, optimización educativa, Industria 5.0, innovación centrada en el ser humano.
- INTRODUCCIÓN
La personalización del aprendizaje es uno de los retos principales en la educación superior, especialmente en campos técnicos como la ingeniería industrial. Los métodos tradicionales de enseñanza, que suelen ser homogéneos, no logran adaptarse a las necesidades específicas de los estudiantes, con lo cual se afecta negativamente su rendimiento académico y su desarrollo profesional.
En respuesta a estos desafíos, el paradigma de la Industria 5.0 promueve la integración de tecnologías avanzadas con un enfoque centrado en el ser humano. En este contexto, el modelo Alfa-Pi-Mi utiliza redes neuronales para analizar datos educativos y generar recomendaciones personalizadas, fomentando una colaboración efectiva entre humanos y máquinas.
El presente artículo detalla el diseño, implementación y evaluación inicial del modelo Alfa-Pi-Mi. Este modelo no solo se alinea con los principios de personalización de la Industria 5.0, sino que también plantea nuevas oportunidades para transformar la educación superior.
- DESARROLLO DE CONTENIDOS
- Arquitectura del Modelo Alfa-Pi-Mi
El modelo Alfa-Pi-Mi emplea una arquitectura multicapa que permite procesar datos complejos y generar estrategias educativas adaptativas. Las principales características de su arquitectura incluyen:
- Capa de Entrada: Representa las variables clave del rendimiento académico, como:
- Exámenes: indicadores de desempeño académico cuantitativo.
- Estilo de aprendizaje: preferencias individuales que guían la personalización.
- Historial de rendimiento: datos históricos que identifican tendencias.
- Participación: indicador del nivel de interacción en actividades académicas.
- Estrés: factores psicológicos que afectan el desempeño.
- Intervenciones previas: resultados de estrategias aplicadas previamente.
2. Capas Ocultas: Procesan los datos a través de dos capas con ocho neuronas cada una, utilizando funciones de activación como ReLU y Tanh para identificar patrones complejos.
3. Capa de Salida: Genera predicciones y recomendaciones personalizadas, como estrategias educativas e intervenciones inmediatas.
B. Funciones de Activación y Métodos de Optimización
El modelo utiliza funciones de activación específicas para manejar la complejidad de los datos:
- ReLU: introduce no linealidad, lo cual permite aprender patrones complejos.
- Sigmoide: calcula probabilidades útiles para clasificaciones específicas.
- Tanh: ideal para datos centrados en torno a cero, con lo que se mejora la convergencia.
En cuanto a la optimización, se emplea el algoritmo Adam (Adaptive Moment Estimation), que combina técnicas de gradiente descendente y promedio móvil. Esto asegura que el modelo sea eficiente en términos de convergencia y estabilidad.
C. Metodología
- Diseño del Modelo
El modelo Alfa-Pi-Mi fue entrenado con un conjunto de datos inicial de 30 estudiantes. Los hiperparámetros principales incluyeron:
- Una tasa de aprendizaje inicial de 0.001.
- 100 ciclos de entrenamiento.
- Implementación Piloto
Durante la prueba piloto, se aplicaron simulaciones adaptativas y estrategias personalizadas en cinco áreas académicas clave:
- Optimización y Modelos Matemáticos
- Estadística y Métodos Cuantitativos
- Gestión de Producción
- Gestión de Proyectos
- Ingeniería de Calidad
D. Resultados Observados
Progresión Semanal
Los estudiantes mostraron mejoras significativas en todas las áreas evaluadas,
como se observa en Fig. 2.
Distribución de Estudiantes
Más del 60% de los estudiantes lograron mejoras moderadas o altas, reflejando el impacto positivo de las intervenciones personalizadas (Fig. 3).
III. LIMITACIONES DEL MODELO
A. Limitaciones Técnicas
- Dependencia de la Calidad de los Datos: Datos faltantes o sesgados afectan la precisión del modelo.
- Complejidad Computacional: La implementación requiere infraestructura avanzada, lo que puede limitar su adopción.
- Sobreajuste: El modelo necesita datos más amplios para evitar aprender patrones específicos de pequeños conjuntos.
B. Limitaciones de Implementación
- Escalabilidad: Aunque efectivo en pequeños grupos, el modelo requiere ajustes para aplicarse a poblaciones mayores.
- Curva de Aprendizaje para Usuarios: Los educadores necesitan capacitación para interpretar las recomendaciones del modelo.
C. Aspectos Éticos y de Privacidad
- Privacidad de los Datos: Es crucial proteger la información sensible de los estudiantes.
- Transparencia: El modelo debe ser más interpretable para fomentar la confianza en sus recomendaciones.
IV. RESULTADOS
Las figuras y la tabla proporcionan una visión integral del impacto del modelo Alfa- Pi-Mi.
- Figura. 1: Explica cómo el modelo estructura y procesa los datos.
- 2 y Fig. 3: Destacan cómo los estudiantes progresaron a lo largo de la prueba piloto y en qué medida lograron mejoras significativas.
- Tabla I: Cuantifica las mejoras observadas, ofreciendo datos claros que respaldan la efectividad del modelo.
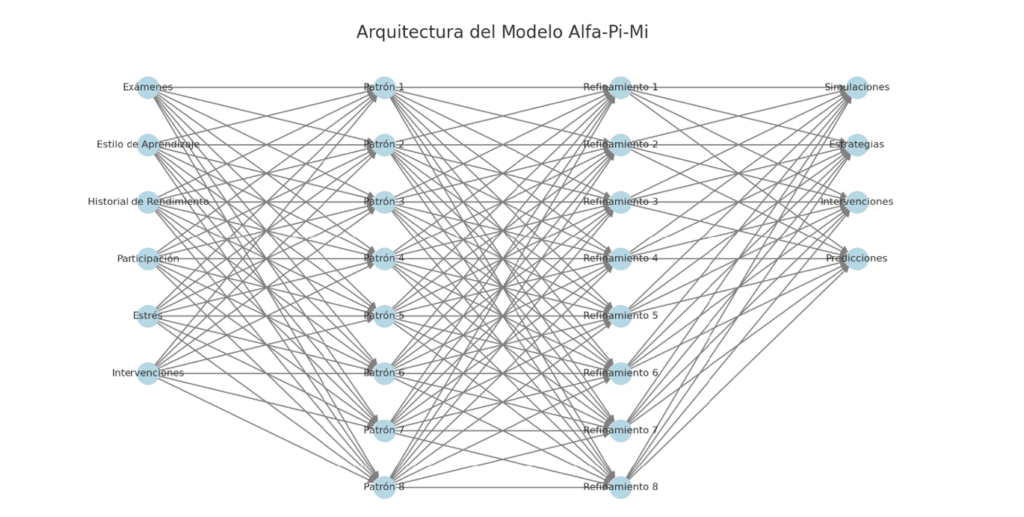
Fig. 1: Arquitectura del Modelo Alfa-Pi-Mi
Esta figura representa la estructura general del modelo Alfa-Pi-Mi, diseñada para procesar datos educativos y generar estrategias personalizadas. Se compone de tres capas principales:
1.Capa de Entrada: Incluye seis variables fundamentales: exámenes, estilo de aprendizaje, historial de rendimiento, participación, estrés e intervenciones previas. Estas variables sirven como insumos para alimentar el modelo con información crítica sobre cada estudiante.
2.Capas Ocultas: Dos capas de ocho neuronas procesan los datos utilizando funciones de activación como ReLU y Tanh, lo que permite identificar patrones complejos y relaciones entre las variables.
3.Capa de Salida: Produce cuatro tipos de resultados: simulaciones personalizadas, estrategias educativas específicas, evaluaciones de la necesidad de intervención inmediata y predicciones de rendimiento académico futuro.
La arquitectura refleja cómo la información fluye desde las variables de entrada, pasa por el procesamiento interno y culmina en recomendaciones accionables para los educadores.
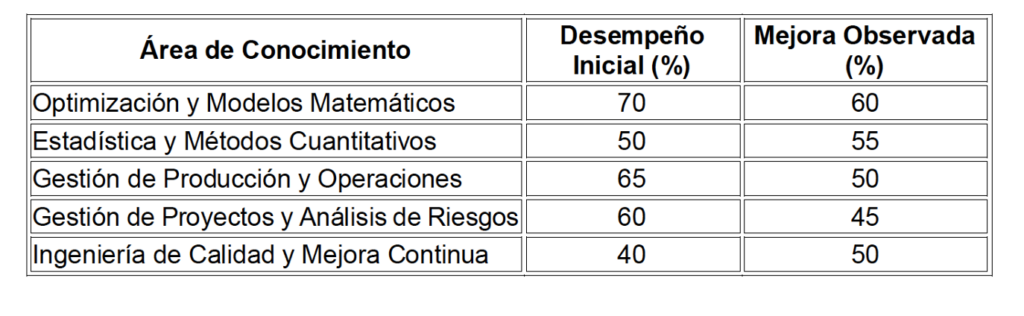
Esta tabla resume los resultados obtenidos en cinco áreas académicas clave antes y después de aplicar el modelo.
- Desempeño Inicial: Refleja el porcentaje promedio de dominio antes de la intervención.
- Mejora Observada: Indica el porcentaje adicional logrado al final de la prueba piloto.
Interpretación:
- Optimización y Estadística: Estas áreas mostraron las mayores mejoras absolutas, evidenciando que el modelo es más efectivo en disciplinas que requieren razonamiento lógico y análisis cuantitativo.
- Ingeniería de Calidad: Aunque comenzó con el desempeño inicial más bajo (40%), mostró una mejora significativa (50%), lo que resalta el potencial del modelo para apoyar áreas tradicionalmente desafiantes.
- Gestión de Proyectos: Aunque la mejora fue más limitada (45%), esto podría deberse a la naturaleza cualitativa de la disciplina, que requiere enfoques pedagógicos distintos.
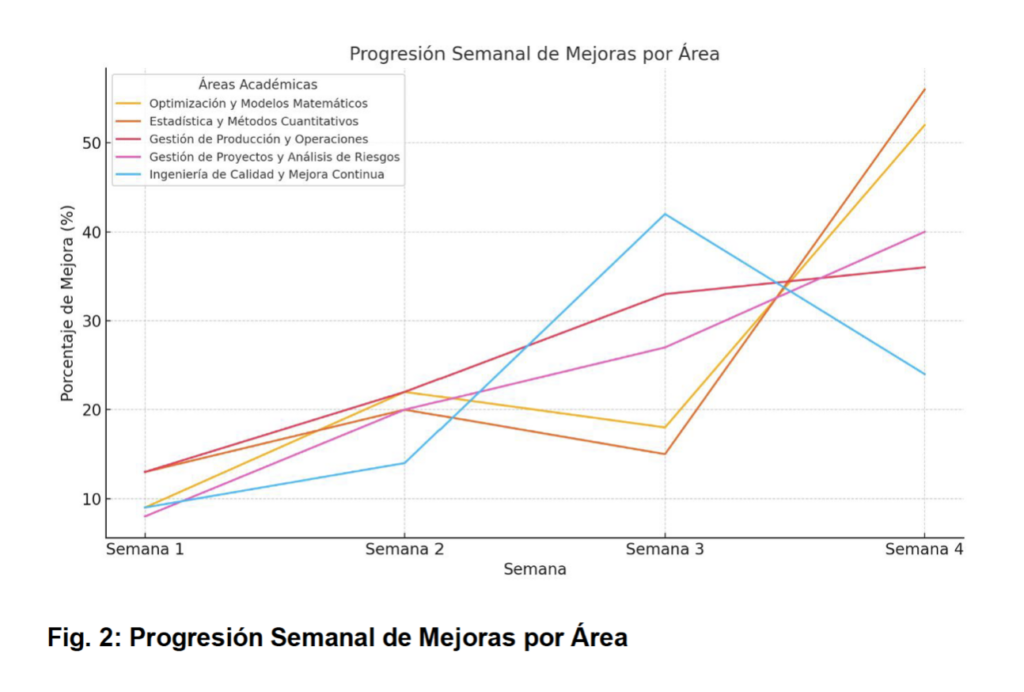
Esta figura ilustra cómo las áreas académicas clave mejoraron semana a semana durante la prueba piloto de cuatro semanas.
- Interpretación del Gráfico: Cada línea representa un área académica (Optimización, Estadística, etc.). El eje vertical muestra el porcentaje de mejora acumulado, mientras que el eje horizontal indica las semanas.
- Observaciones Clave:
- Las áreas con mayores avances fueron «Optimización y Modelos Matemáticos» y «Estadística», mostrando un incremento constante en el rendimiento.
- Las mejoras son más pronunciadas en las semanas 3 y 4, lo que sugiere que el modelo requiere cierto tiempo para identificar patrones y optimizar las recomendaciones.
Este gráfico evidencia que el modelo puede impactar positivamente áreas específicas cuando se implementa de manera continua.
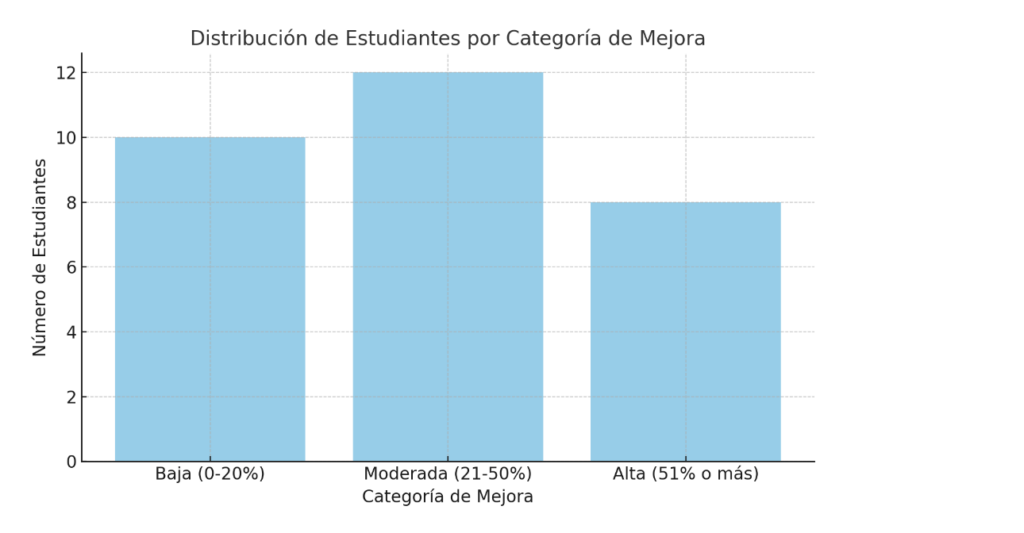
Fig. 3: Distribución de Estudiantes por Categoría de Mejora
La figura presenta la proporción de estudiantes agrupados por el nivel de mejora alcanzado al final de la prueba piloto:
- Baja (0–20%): Representa a los estudiantes con mejoras mínimas. Esto puede deberse a factores externos, como estrés elevado o baja participación.
- Moderada (21–50%): El grupo mayoritario se encuentra en esta categoría, lo que indica que el modelo logró impactar a una amplia base de estudiantes.
- Alta (51% o más): Este grupo incluye a los estudiantes que experimentaron las mejoras más significativas, demostrando el potencial del modelo para transformar el rendimiento académico en casos favorables.
Esta distribución valida la capacidad del modelo para generar impactos positivos en diversos niveles, aunque destaca la necesidad de seguir optimizando la personalización para estudiantes con bajas mejoras.
V. CONCLUSIONES
El modelo Alfa-Pi-Mi, basado en principios de la Industria 5.0, representa una herramienta poderosa para personalizar el aprendizaje y mejorar el rendimiento académico. A pesar de sus limitaciones, los resultados iniciales son prometedores y sugieren un alto potencial para transformar la educación superior.
REFERENCIAS
[1] I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning. MIT Press, 2016. [2] Universidad Continental, II Convención Internacional de Innovación en Ingeniería y V Congreso Internacional de Ingeniería: Industria 5.0, Arequipa, Perú, 2023.
Resumen
Este documento presenta el diseño e implementación del modelo de redes neuronales Alfa-Pi-Mi, para personalizar y optimizar el aprendizaje de estudiantes de ingeniería industrial, aplicando inteligencia artificial. Utilizando redes neuronales, el modelo identifica patrones de aprendizaje y propone estrategias personalizadas. Este trabajo detalla la arquitectura del modelo, incluyendo el impacto de las variables de entrada, las funciones de activación y los métodos de optimización utilizados. Una prueba piloto evidenció mejoras significativas en áreas clave como optimización y estadística. Además, se analizan las limitaciones técnicas, éticas y su alineación con los principios de la Industria 5.0.
Palabras clave: redes neuronales, aprendizaje personalizado, inteligencia artificial en educación, Alfa-Pi-Mi, optimización educativa, Industria 5.0, innovación centrada en el ser humano.
- INTRODUCCIÓN
La personalización del aprendizaje es uno de los retos principales en la educación superior, especialmente en campos técnicos como la ingeniería industrial. Los métodos tradicionales de enseñanza, que suelen ser homogéneos, no logran adaptarse a las necesidades específicas de los estudiantes, con lo cual se afecta negativamente su rendimiento académico y su desarrollo profesional.
En respuesta a estos desafíos, el paradigma de la Industria 5.0 promueve la integración de tecnologías avanzadas con un enfoque centrado en el ser humano. En este contexto, el modelo Alfa-Pi-Mi utiliza redes neuronales para analizar datos educativos y generar recomendaciones personalizadas, fomentando una colaboración efectiva entre humanos y máquinas.
El presente artículo detalla el diseño, implementación y evaluación inicial del modelo Alfa-Pi-Mi. Este modelo no solo se alinea con los principios de personalización de la Industria 5.0, sino que también plantea nuevas oportunidades para transformar la educación superior.
- DESARROLLO DE CONTENIDOS
- Arquitectura del Modelo Alfa-Pi-Mi
El modelo Alfa-Pi-Mi emplea una arquitectura multicapa que permite procesar datos complejos y generar estrategias educativas adaptativas. Las principales características de su arquitectura incluyen:
- Capa de Entrada: Representa las variables clave del rendimiento académico, como:
- Exámenes: indicadores de desempeño académico cuantitativo.
- Estilo de aprendizaje: preferencias individuales que guían la personalización.
- Historial de rendimiento: datos históricos que identifican tendencias.
- Participación: indicador del nivel de interacción en actividades académicas.
- Estrés: factores psicológicos que afectan el desempeño.
- Intervenciones previas: resultados de estrategias aplicadas previamente.
2. Capas Ocultas: Procesan los datos a través de dos capas con ocho neuronas cada una, utilizando funciones de activación como ReLU y Tanh para identificar patrones complejos.
3. Capa de Salida: Genera predicciones y recomendaciones personalizadas, como estrategias educativas e intervenciones inmediatas.
B. Funciones de Activación y Métodos de Optimización
El modelo utiliza funciones de activación específicas para manejar la complejidad de los datos:
- ReLU: introduce no linealidad, lo cual permite aprender patrones complejos.
- Sigmoide: calcula probabilidades útiles para clasificaciones específicas.
- Tanh: ideal para datos centrados en torno a cero, con lo que se mejora la convergencia.
En cuanto a la optimización, se emplea el algoritmo Adam (Adaptive Moment Estimation), que combina técnicas de gradiente descendente y promedio móvil. Esto asegura que el modelo sea eficiente en términos de convergencia y estabilidad.
C. Metodología
- Diseño del Modelo
El modelo Alfa-Pi-Mi fue entrenado con un conjunto de datos inicial de 30 estudiantes. Los hiperparámetros principales incluyeron:
- Una tasa de aprendizaje inicial de 0.001.
- 100 ciclos de entrenamiento.
- Implementación Piloto
Durante la prueba piloto, se aplicaron simulaciones adaptativas y estrategias personalizadas en cinco áreas académicas clave:
- Optimización y Modelos Matemáticos
- Estadística y Métodos Cuantitativos
- Gestión de Producción
- Gestión de Proyectos
- Ingeniería de Calidad
D. Resultados Observados
Progresión Semanal
Los estudiantes mostraron mejoras significativas en todas las áreas evaluadas,
como se observa en Fig. 2.
Distribución de Estudiantes
Más del 60% de los estudiantes lograron mejoras moderadas o altas, reflejando el impacto positivo de las intervenciones personalizadas (Fig. 3).
III. LIMITACIONES DEL MODELO
A. Limitaciones Técnicas
- Dependencia de la Calidad de los Datos: Datos faltantes o sesgados afectan la precisión del modelo.
- Complejidad Computacional: La implementación requiere infraestructura avanzada, lo que puede limitar su adopción.
- Sobreajuste: El modelo necesita datos más amplios para evitar aprender patrones específicos de pequeños conjuntos.
B. Limitaciones de Implementación
- Escalabilidad: Aunque efectivo en pequeños grupos, el modelo requiere ajustes para aplicarse a poblaciones mayores.
- Curva de Aprendizaje para Usuarios: Los educadores necesitan capacitación para interpretar las recomendaciones del modelo.
C. Aspectos Éticos y de Privacidad
- Privacidad de los Datos: Es crucial proteger la información sensible de los estudiantes.
- Transparencia: El modelo debe ser más interpretable para fomentar la confianza en sus recomendaciones.
IV. RESULTADOS
Las figuras y la tabla proporcionan una visión integral del impacto del modelo Alfa- Pi-Mi.
- Figura. 1: Explica cómo el modelo estructura y procesa los datos.
- 2 y Fig. 3: Destacan cómo los estudiantes progresaron a lo largo de la prueba piloto y en qué medida lograron mejoras significativas.
- Tabla I: Cuantifica las mejoras observadas, ofreciendo datos claros que respaldan la efectividad del modelo.
Fig. 1: Arquitectura del Modelo Alfa-Pi-Mi
Esta figura representa la estructura general del modelo Alfa-Pi-Mi, diseñada para procesar datos educativos y generar estrategias personalizadas. Se compone de tres capas principales:
1.Capa de Entrada: Incluye seis variables fundamentales: exámenes, estilo de aprendizaje, historial de rendimiento, participación, estrés e intervenciones previas. Estas variables sirven como insumos para alimentar el modelo con información crítica sobre cada estudiante.
2.Capas Ocultas: Dos capas de ocho neuronas procesan los datos utilizando funciones de activación como ReLU y Tanh, lo que permite identificar patrones complejos y relaciones entre las variables.
3.Capa de Salida: Produce cuatro tipos de resultados: simulaciones personalizadas, estrategias educativas específicas, evaluaciones de la necesidad de intervención inmediata y predicciones de rendimiento académico futuro.
La arquitectura refleja cómo la información fluye desde las variables de entrada, pasa por el procesamiento interno y culmina en recomendaciones accionables para los educadores.
Esta tabla resume los resultados obtenidos en cinco áreas académicas clave antes y después de aplicar el modelo.
- Desempeño Inicial: Refleja el porcentaje promedio de dominio antes de la intervención.
- Mejora Observada: Indica el porcentaje adicional logrado al final de la prueba piloto.
Interpretación:
- Optimización y Estadística: Estas áreas mostraron las mayores mejoras absolutas, evidenciando que el modelo es más efectivo en disciplinas que requieren razonamiento lógico y análisis cuantitativo.
- Ingeniería de Calidad: Aunque comenzó con el desempeño inicial más bajo (40%), mostró una mejora significativa (50%), lo que resalta el potencial del modelo para apoyar áreas tradicionalmente desafiantes.
- Gestión de Proyectos: Aunque la mejora fue más limitada (45%), esto podría deberse a la naturaleza cualitativa de la disciplina, que requiere enfoques pedagógicos distintos.
Esta figura ilustra cómo las áreas académicas clave mejoraron semana a semana durante la prueba piloto de cuatro semanas.
- Interpretación del Gráfico: Cada línea representa un área académica (Optimización, Estadística, etc.). El eje vertical muestra el porcentaje de mejora acumulado, mientras que el eje horizontal indica las semanas.
- Observaciones Clave:
- Las áreas con mayores avances fueron «Optimización y Modelos Matemáticos» y «Estadística», mostrando un incremento constante en el rendimiento.
- Las mejoras son más pronunciadas en las semanas 3 y 4, lo que sugiere que el modelo requiere cierto tiempo para identificar patrones y optimizar las recomendaciones.
Este gráfico evidencia que el modelo puede impactar positivamente áreas específicas cuando se implementa de manera continua.
Fig. 3: Distribución de Estudiantes por Categoría de Mejora
La figura presenta la proporción de estudiantes agrupados por el nivel de mejora alcanzado al final de la prueba piloto:
- Baja (0–20%): Representa a los estudiantes con mejoras mínimas. Esto puede deberse a factores externos, como estrés elevado o baja participación.
- Moderada (21–50%): El grupo mayoritario se encuentra en esta categoría, lo que indica que el modelo logró impactar a una amplia base de estudiantes.
- Alta (51% o más): Este grupo incluye a los estudiantes que experimentaron las mejoras más significativas, demostrando el potencial del modelo para transformar el rendimiento académico en casos favorables.
Esta distribución valida la capacidad del modelo para generar impactos positivos en diversos niveles, aunque destaca la necesidad de seguir optimizando la personalización para estudiantes con bajas mejoras.
V. CONCLUSIONES
El modelo Alfa-Pi-Mi, basado en principios de la Industria 5.0, representa una herramienta poderosa para personalizar el aprendizaje y mejorar el rendimiento académico. A pesar de sus limitaciones, los resultados iniciales son prometedores y sugieren un alto potencial para transformar la educación superior.
REFERENCIAS
[1] I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning. MIT Press, 2016. [2] Universidad Continental, II Convención Internacional de Innovación en Ingeniería y V Congreso Internacional de Ingeniería: Industria 5.0, Arequipa, Perú, 2023.